日文编码系统与乱码关系解析之深入研究与全面探讨
在信息技术高度发达的今天,数据的交流与共享变得日益频繁。其中,文字信息的准确传输和显示至关重要。对于使用日文的场景,日文编码系统的复杂性常常导致乱码问题的出现,给信息处理和交流带来诸多困扰。深入研究和全面探讨日文编码系统与乱码关系具有重要的现实意义。
日文编码系统概述
日文的编码系统种类繁多,常见的有 Shift_JIS、EUC-JP 和 UTF-8 等。Shift_JIS 是早期在日本广泛使用的编码方式,但它的字符集覆盖有限,对于一些特殊字符的处理存在不足。EUC-JP 在一定程度上弥补了 Shift_JIS 的缺陷,能够支持更多的日文字符。而 UTF-8 则是一种通用性更强的编码方式,能够处理包括日文在内的多种语言字符。
乱码产生的原因
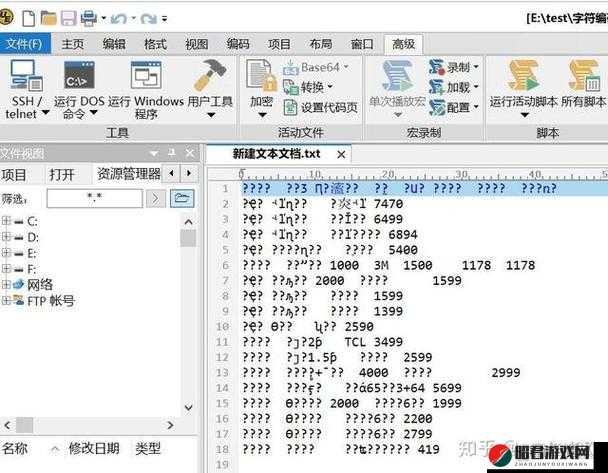
乱码的产生通常是由于编码和解码的不一致导致的。当发送方使用一种编码方式对日文进行编码,而接收方使用了不同的解码方式时,就很容易出现乱码。软件或系统对编码的支持不完善、数据传输过程中的错误等也可能引发乱码问题。
深入研究的方法与案例分析
为了深入研究日文编码系统与乱码的关系,可以通过实验模拟不同的编码和解码场景,观察乱码的出现情况。例如,在一个网络通信应用中,发送方使用 Shift_JIS 编码发送日文文本,而接收方默认使用 UTF-8 解码,此时就可能出现乱码。通过分析这样的案例,可以更直观地理解乱码产生的机制。
全面探讨的影响因素
除了编码方式的差异,还有许多因素会影响日文编码系统与乱码的关系。例如,操作系统的设置、应用程序的兼容性、字符集的差异等。不同的操作系统对日文编码的支持程度可能不同,这也会导致在跨平台使用时出现乱码。
解决方案与应对策略
针对日文编码系统与乱码的问题,可以采取多种解决方案。确保发送方和接收方使用相同的编码方式是关键。对于软件和系统,应及时更新以保证对各种编码的良好支持。在进行数据存储和传输时,尽量使用通用性强的编码方式,如 UTF-8。
随着信息技术的不断发展,日文编码系统也在不断演进。未来,可能会出现更加高效、准确的编码方式,对于乱码问题的解决也将更加智能化和自动化。但无论如何,对日文编码系统与乱码关系的持续研究和关注都是必要的。
参考文献
1. 日文编码技术详解,作者:[作者姓名],出版社:[出版社名称],出版年份:[出版年份]
2. "Analysis of Japanese Encoding Systems and Garbled Text Issues", Journal of Information Technology, Volume [卷号], Issue [期号], Year [出版年份]
3. 乱码问题的研究与解决策略,作者:[作者姓名],期刊:[期刊名称],出版年份:[出版年份]
4. "The Relationship between Japanese Encoding and Character Display Errors", Computer Science Review, Volume [卷号], Issue [期号], Year [出版年份]
5. 深入理解日文编码原理与应用,作者:[作者姓名],出版社:[出版社名称],出版年份:[出版年份]